


一、核心定位
node-exporter 是 Prometheus 官方提供的服务器硬件 / 系统指标采集器,运行在被监控服务器本地,通过读取系统底层接口、文件、命令采集硬件、内核、磁盘、网络、CPU、内存等指标,对外提供 HTTP /metrics 接口供 Prometheus 拉取。
二、数据采集底层来源(Linux 为主)
1. 核心数据源:/proc 虚拟文件系统(内核实时信息)
/proc 是 Linux 内核导出运行时状态的虚拟目录,node-exporter 绝大部分指标来自这里:
| 文件路径 | 采集指标 |
|---|---|
| /proc/cpuinfo | CPU 型号、核心数、主频 |
| /proc/stat | CPU 各模式占用(user/system/idle/iowait)、中断、上下文切换 |
| /proc/meminfo | 总内存、可用内存、缓存、Swap 用量 |
| /proc/diskstats | 磁盘读写 IO、扇区、IO 耗时 |
| /proc/net/dev | 网卡收发包、字节、丢包、错误包 |
| /proc/loadavg | 1/5/15 分钟系统负载 |
| /proc/uptime | 服务器运行时长 |
| /proc/sys/fs/file-nr | 文件句柄使用量 |
| /proc/mounts | 挂载点、磁盘分区使用率 |
2. /sys 设备硬件信息(硬件、块设备、电源、温度)
/sys 是 sysfs 文件系统,存放硬件设备标准化信息:
- 磁盘型号、扇区大小、RAID 信息
- CPU 温度、风扇转速(
/sys/class/hwmon/) - 电源、电池状态(物理机 / 笔记本)
3. 系统调用 & 标准工具封装
部分指标无法直接读文件,node-exporter 通过 Go 系统调用封装实现:
- 文件系统使用率:封装
statfs()系统调用,等价df -h - 系统时间、时区:系统时间调用
- 硬件信息:读取 DMI 信息
/sys/devices/virtual/dmi/id/(主板、序列号、厂商) - 磁盘分区标签:解析 blkid 信息
4. 可选采集器(额外开启)
node-exporter 内置多组 collector,默认只开启基础采集,部分需手动启用:
systemd:读取 systemd 服务运行状态(journal、服务启停)arp:ARP 连接表ipvs:LVS 负载均衡状态raid:软 RAID mdstat 状态hwmon:硬件温度传感器smart:硬盘 SMART 健康信息(需 root)logind:登录会话、用户在线数
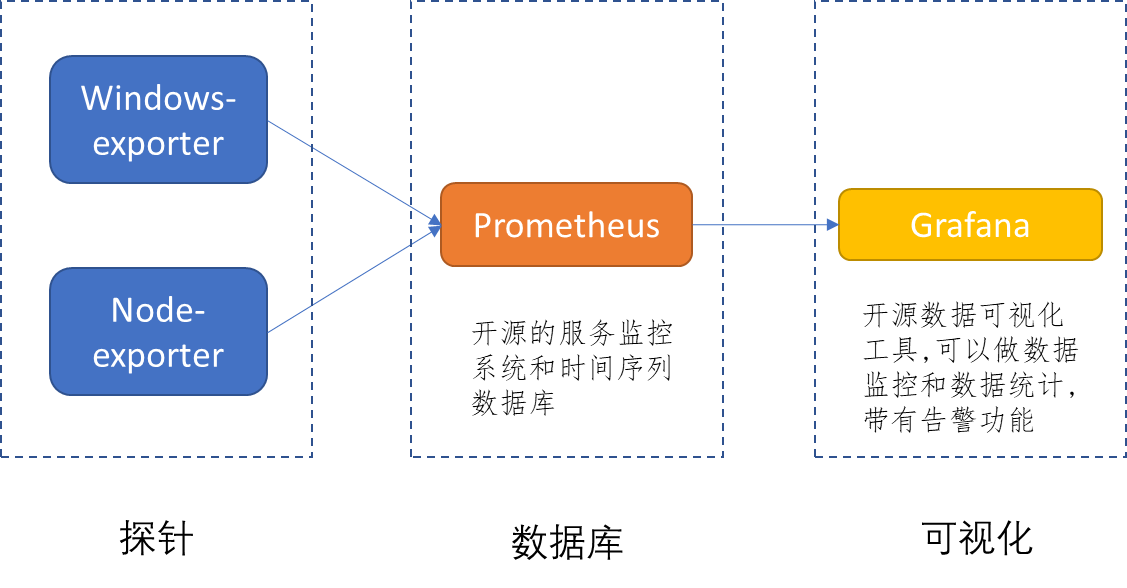
三、完整数据流转流程
步骤 1:node-exporter 启动加载采集器
- 进程启动时加载内置 Collector(CPU、mem、disk、net 等);
- 根据启动参数
--collector.xxx开启 / 关闭对应采集模块; - 绑定默认端口 9100,启动 HTTP 服务。
步骤 2:Prometheus 定时发起拉取(核心逻辑:Pull 模式)
Prometheus 配置 scrape_configs 定义目标:
scrape_configs:
- job_name: "node"
static_configs:
- targets: ["192.168.1.100:9100"] # 被监控机 node-exporter 地址
每隔 scrape_interval(默认 15s)发送 HTTP GET 请求:
GET http://192.168.1.100:9100/metrics
步骤 3:node-exporter 实时采集系统数据
收到 /metrics 请求后同步执行全量采集(每次拉取重新读取系统文件,无本地缓存):
- 依次遍历所有启用的 Collector;
- 读取
/proc//sys、调用系统函数获取原始数值; - 原始数据标准化转换为 Prometheus 格式指标(key-value + label); 示例输出:
node_memory_MemTotal_bytes 16679440384
node_cpu_seconds_total{cpu="0",mode="idle"} 123456.78
node_disk_io_time_seconds_total{device="vda"} 789.12
- 增加内置标签:
instance(服务器地址)、job等。
步骤 4:数据返回 & Prometheus 存储
- node-exporter 将文本格式指标返回给 Prometheus;
- Prometheus 解析指标,存入本地时序数据库 TSDB;
- Grafana 查询 Prometheus 数据做可视化展示。
四、关键特性细节
- 无推送逻辑 node-exporter 不会主动上报数据,始终被动等待 Prometheus 拉取;
- 无持久化存储 采集的数据仅存在内存,请求结束即销毁,时序数据完全由 Prometheus 保存;
- 权限影响采集范围
- 普通用户:只能获取基础 CPU、内存、网络;
- root 用户:可读取 SMART 硬盘健康、硬件温度、raid、systemd 完整状态;
- 采集性能 读取 /proc 是内存虚拟文件,IO 开销极低,单台机器 node-exporter CPU 占用几乎可忽略;大量磁盘 / 传感器采集才会轻微增加耗时;
- 过滤不需要的指标 通过
--no-collector.xxx关闭无用采集器减少输出,例如:
./node-exporter --no-collector.arp --no-collector.ipvs
五、Windows 环境差异补充
Windows 版 node-exporter 不再读取 /proc,底层调用 Windows API:
- 性能计数器(PerfCounter)获取 CPU、内存、磁盘;
- WMI 接口读取硬件、系统服务、网卡信息; 采集逻辑一致:本地采集 → 9100 端口 /metrics → Prometheus 拉取。
六、常用验证命令
在被监控服务器直接查看原始指标,验证采集是否正常:
# 本机访问 metrics 接口 curl http://127.0.0.1:9100/metrics # 过滤内存指标 curl http://127.0.0.1:9100/metrics | grep node_memory